DataBots
S. L. Thaler
US Patent 5,659,666, US Patent 5,845,271, US Patent 5,852,815, US Patent 5,852,816

ABSTRACT - The ability to form extensive cell reference networks within typical spreadsheet applications lends itself well to emulating the central nervous systems of simple organisms. Exploiting this capability, we have successfully created artificial neurons, neural networks, and neural network cascades within Microsoft Excel worksheets. The resulting synthetic neurobiology not only forms the basis of adaptive artificial life, but also the foundation for automated knowledge base agents. These agents may (1) exercise their independent judgments in perusing databases, (2) choose their own perspective on or physically move through the data, (3) automatically learn hidden data patterns, and (4) cooperatively build compound cascade structures capable of autonomous discovery and invention. Provided that data passes through the spreadsheet environment, such "DataBots," acting alone or in concert, observe, generalize, and manipulate that influx of information. They may fulfill the whims of human researchers or, based upon their initiatives, exhaust a database of all potential discoveries. Advanced DataBot forms may autonomously assemble the needed algorithmic agents to infiltrate and explore larger databases external to their spreadsheet origin.
In this paper we review the principles underlying DataBot construction and function, drawing a one-to-one correspondence with the biological capabilities of advanced adaptive organisms. We show how DataBots achieve vision, attention, visual processing, novel feature detection, movement, learning, reproduction, and creativity using simple spreadsheet properties and methods. Drawing parallels with the notion of encapsulation in object-oriented programming, we also see how such DataBots achieve autonomy from both operator and operator-conceived algorithms. Related discussion then focuses on the DataBot's intentionality as self-originated decisions arise by allowing a supervised chaotic network to imagine various action scenarios through the so-called "Creativity Machine Paradigm."
Offered tens of millions of cells within current spreadsheet applications and the possibility of increasing those numbers by several orders of magnitude in the future, we speculate on the potential and future applications of the DataBot principle.
1. The Synthetic Central Nervous System
A very powerful and flexible means of constructing and operating various parallel computing architectures is by means of spreadsheet techniques. We may implement Individual processing units, networks, and network cascades by the exclusive use of only cell references and resident spreadsheet functions. In Figure 1, for instance, we illustrate synaptic integration and output squashing using only relative cell references and a sigmoidal transfer function. The result is a neuron that is highly reproducible and transportable. As a consequence, we may join neurons into neural networks, and these networks into neural network cascades, all of which share the same mobility. We are at liberty to copy, cut, and paste these networks into arbitrarily complex architectures, freely interconnecting computational units and building any degree of recurrencies needed. If desired, we may even embed neural network models of actual biological neurons to serve as the individual processing units.
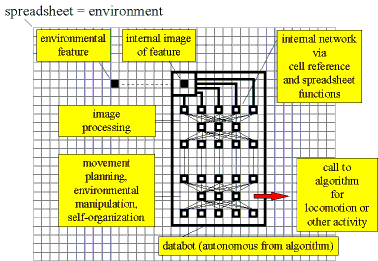
In the intelligent search of massive databases, we would like to create intelligent software agents that embody the human attributes of self-initiative, adaptivity, and creativity toward the objective of data management and discovery. To achieve this goal, the Excel spreadsheet application supplies a convenient neural network development environment within which we may prototype and refine the necessary neural cascades to emulate the needed human-like brain pathways. In essence, we seek to broadly simulate the human central nervous system (CNS) using the spreadsheet using only spreadsheet resources. In correspondence to the biological situation, spreadsheet data now represents general sensory stimuli. Various spreadsheet-based associative networks may then parcel out these raw sensory inputs to subsequent and more specialized processing centers, thus emulating modularization within the brain. Subsequent spreadsheet networks may then 'invent' new courses of action within the context of the sensed environment and stored memories using the so-called "Creativity Machine Paradigm" or CM, described in more detail below. Finally, in affecting its environment, instead of using limbs and appendages, the distributed algorithm represented by the spreadsheet cascade may then direct a strictly algorithm code or 'slave macro' to carry out some action or movement solely originated within that cascade.

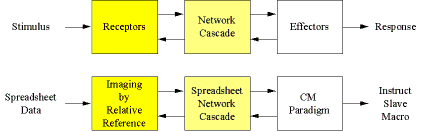
In this paper we discuss the achievement of all the processing stages depicted in Figure 2, within the Excel neural network development environment, and then describe several experiments within which the underlying principles have been reduced to practice. The result is a tool kit with which to synthesize these adaptive spreadsheet agents, we call "DataBots." These DataBots may then patrol and manipulate static data bases as well as monitor and learn from data streams supplied through dynamic data exchange (DDE) to Excel.
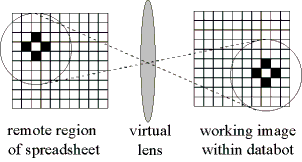
2. DataBot Receptors
Sensory inputs to the DataBot are primarily 'visual', based on the notion of locating and interpreting data resident within a spreadsheet application. In so doing, the DataBot must produce some working replica of its data environment prior to deeper visual processing (Figure 3). In analogy to the formation of a retinal image in neurobiology, the DataBot forms at least one working replica of its target data by relative cell reference. In some cases, this image may be as simple as single numeric values, as in supplying the input values to a feedthrough network. Within other requirements, the working image formed may represent a larger receptive field containing a cluster or grouping of spreadsheet objects.
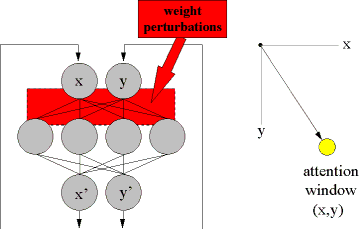
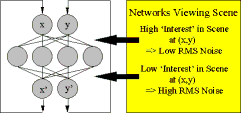
Central to DataBot function, this synthetic organism must be able to scan the environment within its vicinity. One such scheme that I have successfully used to facilitate such a visual scanning process involves the emulation of the neurobiological strategies known as population coding and vector averaging (Churchland & Sejnowski, 1992). In such processes an external sensory organ follows the 'center of gravity' of activation among a colony of highly interconnected neurons. In the brain, for instance, the superior colliculus is a type of "where to foveate next" map for the eyeballs. The final directions of movement and resting position depend upon all the neurons in the colony contributing activity to various degrees. I have used recurrent associative networks, as exemplified in Figure 4, to implement this type of chaotic scan. By constantly recirculating the outputs x'-y' back to the inputs x-y, simultaneously introducing internal perturbations to the network's connection weights, the attention window centered at x-y wanders the spreadsheet in search of specific spreadsheet items. Apart from its observed speed, the major advantage of this search technique is that activation from networks viewing items within this attention window may modulate and hence diminish the rms noise amplitude applied to network weights. Because of this feedback, the point of foveation tends to gravitate toward and ultimately center on objects of interest (Figures 5 & 6).
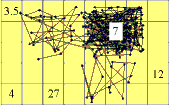
Often the DataBot must be able to quickly gravitate toward large clusters of information, moving either in the plane of the worksheets or in effectively 3 dimensions, through successive pages of a workbook. To exemplify how to achieve this task, we may imagine DataBot retinas segmented to act as quadrant detectors. Concentrations of data in the x, y, -x, and -y directions register instantaneously to provide an information gradient to the organism. The vector sum of data located in each of these quadrants provides a movement trajectory. Therefore, in seeking specific information, the DataBot will tend to exhaust the larger data clusters before moving on to the more scattered information.
3. The Internal DataBot Network Cascade
The spreadsheet cascades that process the DataBot's raw sensory input (i.e., the central network block of Figure 2) handle several specific tasks including (1) location, (2) identification, (3) learning (4) novel feature detection, (5) attention windowing, and (6) novel movement and activity planning. The first three processing categories represent instances of information processing, while the latter two closely related tasks embody information generation. Here we briefly touch upon each of these levels of internal DataBot function, pointing out the general principles and problems surmounted.
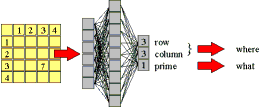
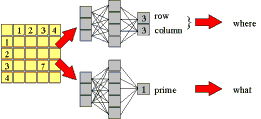
3.1 Location and Identification - The problems of location and identification have been best handled in a manner reminiscent of human visual processing, generally parceling out the preliminary retinotopic maps at the visual cortex into the well-known dorsal and temporal channels. These two channels represent a rough dichotomy of the problem of 'where' and 'what' in visual processing (Kosslyn & Koenig, 1992) and solution to the problem of stimulus equivalence across retinal translation (Gross & Mishkin, 1977; Rueckel, Cave, and Kosslyn, 1989). In Figures 7 and 8, we show how using two separately trained spreadsheet networks we may attain increased classification accuracy. In general, we resort to similar modularization of tasks within the DataBot's synthetic central nervous system.
3.2 Learning - Anticipating that the chief function of the DataBot will be to glean various trends and patterns from massive databases, it will be necessary to incorporate some form of learning paradigm within the DataBot's synthetic CNS. In the spirit of supplying complete autonomy to these spreadsheet agents, we may utilize a novel training technique in which we embed the backpropagation paradigm as a distributed algorithm within a spreadsheet network, connected in turn to an untrained spreadsheet network (Thaler, 1996). It is the backpropagation net that essentially watches both the inputs and output errors of the first and then iteratively adapts connection weights to capture any patterns within the observed data. We accomplish the critical step of calculating the local partial derivatives of neuron activations with respect to net by submitting infinitesimally incremented inputs to a replica network with the backpropagation supervisor net observing the change in neuron activations. Viewing the two interconnected networks as a whole, we may consider it to be a "self-training artificial neural network object" or STANNO, that need only be physically juxtaposed with the training data to spontaneously learn.
3.3 Novel Feature Detection - To sense data generally not falling within the pattern of information cumulatively observed by the DataBot, we may make use of autoassociative nets. Specifically, we find that after training an autoassociative map within any conceptual space of vectors vi, that the application of any vector ve not belonging to that space to the inputs of that autoassociative map produces an output vector ve' differing from ve. In a sense, this phenomenon is analogous to linear matrix theory wherein only the eigenvectors of the transformation remain undistorted following matrix multiplication. Representing the autoassociative net as the nonlinear operator A, the unitary transformation as 1, and the differential vector between network input and output as d,
(A - 1) ve = δ. (1)
Hence, the more unique the vector ve to the majority of data cumulatively 'seen' by the DataBot, the greater will be the magnitude of the vector δ. We may therefore use d as an indicator of pathological or spurious data. Alternatively we may use this difference vector to gate novel information into a self-trainer, sparing it from exposure to redundant training exemplars.
3.4 Attention Windowing - Combining the above ideas of population coding and autoassociative novelty detection, a DataBot may peruse its spreadsheet landscape in search of unique data features, in a manner reminiscent of eye saccades in animals. Using the autoassociative novel detection scheme described above, the DataBot may then dwell on the anomalous feature. It may then elect to self-train on the new item or to perform any number of possible spreadsheet manipulations upon it.
4. DataBot Effectors
Using spreadsheet neural networks typical of those incorporated into DataBot designs, we may create specialized cascades containing tandem pairs of nets in the so-called "Creativity Machine" architecture (Thaler, 1996). Succinctly stated, one of these networks sustains progressively increasing levels of perturbation to its weights and biases, as it activates through a series of states reminiscent first of its training exemplars, then ultimately evolving into generalizations of these exemplars at higher levels of internal disruption. Many of these latter network activations represent confabulations of the unperturbed network's memories, or new ideas, if you will. Many of these new ideas may be of use, being judged as worthy by the second associative network watching the activations of the first, perturbed net. Using this paradigm, we may invent or discover within any arbitrary conceptual space, provided that the requisite database of training exemplars exists.
As an extension and generalization of this creative process, we imagine that the most mundane of DataBot movement or action planning is implementable out by the Creativity Machine paradigm. That is, the perturbed net may represent the memory of the range of movement and past motion scenarios of the DataBot cascade (e.g., its allowed dimensions of travel, steric hindrances to motion due to spreadsheet obstacles, etc.). When internally perturbed, this net visits the entire phase space of potential movement scenarios. The second net may then choose some imagined movement that contributes to some predetermined goal. Constraining the first net by the introduction of auxiliary inputs may assist in further constraining the movement planning search and hence accelerating the DataBot's internal decision process.
We note at this stage that the DataBot is autonomous in the generation of its own decisions. That is, beyond any preliminary network training, the DataBot acts in isolation from either operator or peripheral computer codes. The only access to the DataBot's internal function is by spreadsheet data through its sensory cells. These cells fulfill a role similar to that of the public interface, so familiar within the context of object-oriented programming . The major difference is that the DataBot represents a distributed algorithm rather than a sequential algorithm such as C or C++.
5. Response
In retrospect, we have built a synthetic nervous system, using the many analogies between a spreadsheet cell and an actual biological neuron. The result is a distributed algorithm, embedded within a spreadsheet application and capable of originating its own movement and actions, by imagining such scenarios in advance (Figure 8). Instead of the typical locomotive and manipulative paraphernalia utilized by biological organisms, we may supply the DataBot with recourse to various algorithmic routines (broadly segregated into movement and actions in Figure 9).
In many respects, the DataBot incorporates basic principles behind object oriented programming in that it contains internal data and functions hidden from peripheral algorithmic code (i.e., the underlying spreadsheet machine code and slave macros), from other DataBots, and the operator. The only information to penetrate this encapsulation is sensory data from the spreadsheet environment, with the sensory apparatus being tantamount to the public interface of a class object. Decisions to move, reproduce, or perform manipulation upon data is therefore strictly an internal decision, granting the DataBot (what many would agree) status as an autonomous agent.
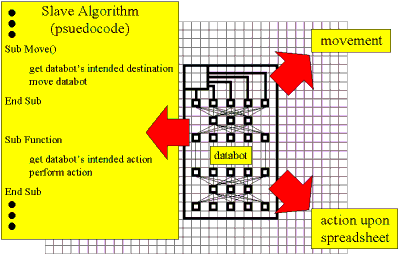
In effecting any given movement imagined by the DataBot, we may enlist any number of simple spreadsheet facilities. For instance, we may achieve incremental or smooth DataBot motion by successive cut and paste commands. Because the DataBot's CNS construction uses relative cell referencing, the synthetic creature relocates itself as an intact, functional unit at its updated position. The net effect is that of continuous translation. Similarly, using copy and paste commands, DataBots may clone, perhaps in response to an increase in data volume and the need for multiple DataBots to take myriad perspectives and training upon the arriving information stream.
6. Applications
Each of these spreadsheet schemes emulates various aspects of CNS function. We may packaged them as individual neural network modules and then link them together to perform a wide variety of functioning DataBots. They would then serve as specialized agents to autonomously perform varied spreadsheet database functions. Below we enumerate just a few potential applications of these virtual organisms utilizing the repertoire of capabilities described above and summarized in Table 1. We mat link together any combination of the modules together within the DataBot's synthetic CNS.
6.1 Database Management - DataBots may exercise their initiative in organizing and manipulating information within spreadsheet databases using many of the principles outlined above. One example already implemented is the detection and isolation of experimental data generally not falling within preexisting patterns. It is a matter of context and DataBot objectives whether to treat such data as pathological or novel. Typically, such DataBots have used the autoassociative principles already described to identify anomalous data vectors, along with either the ability for locomotion among the data or, for static DataBots, a foveation mechanism to scan spreadsheet information. The DataBot then decides autonomously whether to mark that data for the benefit of the operator or to cut and paste such pathologies into an archival location.
One facet of database management already reduced to practice in preliminary experiments is the use of DataBots to search for specific items embedded within a spreadsheet workbook. In these trials, DataBots have been successful in retrieving geometric objects tucked away within a clutter of distracting data. Such work is preliminary to employing DataBots as "store room clerks" that seek various items using content addressing schemes. Therefore it is possible to show a trainbot numerous examples of pentagons, for instance, and have it locate and transport similar shapes to a predetermined collection area within the workbook. In some applications, DataBots have been equipped with special 'enzyme faces' conformal with the objects to be collected. Upon locating the sought item, the DataBot may group itself with the object and then return to the collection point where it commands a slave algorithm to ungroup it from its baggage. Generalizing this principle we may easily envision teams of inventory DataBots that may provided with relatively ambiguous search criteria, ferretting out obscure objects on the basis of a wide variety of criteria.
6.2 Database Discovery - As multiple DataBots, trained on distinct perspectives to the data update themselves in terms of their prediction accuracy, they may autonomously elect to copy and paste themselves into complex Creativity Machine cascades to both create and invent within the specific problem space. That is, these virtual organisms may coordinate into larger collective structures for the purpose of autonomous discovery.
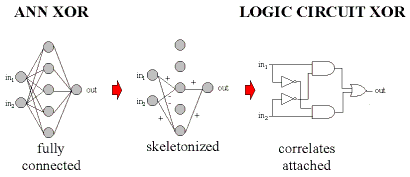
Another important aspect of database discovery deals with the elucidation of various schema stored within the connection weights of an ANN. That is, during training, a network's connection traces grow in magnitude and sign to reflect the logic or models underlying the conceptual space under scrutiny. To reveal such schema, DataBots may successively remove various connection weights from the trained network, on a trial basis, assessing each weight's importance in maintaining the fidelity of mapping. Should we judge any weights superfluous to that mapping, we remove them in a process described as skeletonization (McMillan, Mozer & Smolensky), as exemplified in Figure 11. Teams of DataBots, each trained to recognize neural traces corresponding to various logical, comparative, and arithmetical operations, may overlay corresponding graphical symbols onto the neural network (e.g., AND, OR, and NOT gates) to form a semantic or logical network. In the case of Figure 11, we form a schematic network.
6.3 Robotic Prototyping - With connectionism playing an increased role in cybernetics research, it would be ideal to possess a breadboarding utility to test various robotic principles. That is, before the creation of any hardware such as ROM, we may readily prototype various autonomous movement, vision, and speech facilities. We may then evaluate the function of autonomous agents and devices prior to committing designs to production.
6.4 Infiltration of External Databases - Until now, I have discussed scenarios in which data passes through the spreadsheet application by for instance DDE, where we may apply various data processing stages. It is also possible to allow DataBots to assemble algorithmic code, which may in turn be used to infiltrate larger, external data stores. In preliminary experiments, DataBots have successfully constructed code segments by cutting and pasting Visual Basic program steps into usable macros. That is, the DataBot chooses ASCII commands within the spreadsheet, and then pastes these steps into the VBA macro environment, in the appropriate program order.
6.5 Artificial Life Laboratory - Given this degree of independence, it should be interesting to initiate colonies of these virtual creatures, allowing facilities for mutation and natural selection. The interesting new dimension to this GA type theme is that what is mutating are these creatures' central nervous systems, hopefully evolving into more sophisticated synthetic organisms more adept at data mining and discovery. Perhaps using such techniques we may breed successively smarter intelligent agents.
6.6 Dynamic, Adaptive, Intelligent Agent in a Spreadsheet -DataBots may collectively self-organize into a colonial intelligence capable of human level cognition. Considering the potentially hundreds of millions of spreadsheet neurons possible and the DataBot's inherent self-training facility, it may be possible for DataBots to autonomously assemble first individual brain modules, link such modules, and then collectively train the overall brain structure via the self-training paradigm. The resulting agent would then be capable of conversation, reasoning, and seminal thought.

7. Conclusions
It has been more than a decade since Valentino Breitenberg's (1984) classic work Vehicles, Experiments in Synthetic Psychology, involving a series of thought provoking gedanken experiments with connectionist contraptions that mimicked all aspects of human and animal behavior. In the interim Edelman and coworkers (see, for instance Franklin, 1995) have produced a series of computer models known as selective recognition automata that can categorize, as we do, within largely novel environments. I believe that the DataBot is a useful outgrowth and refinement of these seminal works, culminating in an independent synthetic organism that may prove especially important, not only in the discovery of hidden patterns within massive databases, but for the prototyping of artificial, adaptive life.
Stopping to consider that present day spreadsheet applications may contain 10 or even hundreds of millions of spreadsheet cells, and that any focused cognitive task may invoke similar numbers of biological neurons, it is my opinion that we are at the threshold of emulating human level intelligence. Provided the facility to self-train, all we need add is perceptual input.
8. References
Berry, T.J.(1992). C++ Programming (Carmel: Prentice Hall).
Braitenberg, V. (1984). Experiments in Synthetic Psychology (Cambridge: MIT).
Churchland, P.S. & T.J. Sejnowski (1992). The Computational Brain (Cambridge: MIT) 234-237.
Franklin, S. (1995). Artificial minds (Cambridge: MIT).
Gross, C.G. & Mishkin, M. (1977). The neural basis of stimulus equivalence across retinal translation. In S. Harnad, R. Doty, J. Jaynes, L. Goldstein, & G. Krauthamer (Eds.) , Lateralization in the nervous system (New York: Academic Press).
Kosslyn, S.M. & Koenig, O. (1992). Wet Mind: The New Cognitive Neuroscience, (New York: Free Press), 60-65.
McMillan, C., Mozer, M.C., and Smolensky, P. (1991). Proceedings of IJCNN-International Joint Conference on Neural Networks IJCNN'91 Seattle, Publ. by IEEE, IEEE Service Center, Piscataway, N.J., 83-88.
Rueckel, J.G., Cave, K.R., & Kosslyn, S.M. (1989). Why are "what" and "where" processed by separate cortical systems? A computational investigation. Journal of Cognitive Neuroscience, 1, 171-186.
Rumelhart, D.E., Hinton, G.E., & Williams, R.J. (1986). Parallel distributed processing: Explorations in the microstructure of cognition. Vol. 1 (eds Rumelhart, D.E. & McClelland, J.L.) (Cambridge: MIT)
Thaler, S.L. (1996). Neural networks that create and discover, PC AI, May/June, 1996, 16-21
Thaler, S.L. (1996). Principles and applications of the self-training artificial neural network, Proceedings of the Advanced Distributed Parallel Computing Symposium, ADPC'96, Dayton Ohio.
