LITMUS: Live Intrusion Tracking via Multiple Unsupervised STANNOs*
* Self-Training Artificial Neural Network Objects
Adapted from Infowarcon 2000 and 2001 papers and presentations.

Abstract - The detection of network intrusion is traditionally achieved by capturing the characteristics of confirmed attacks within rule-based algorithms. Subsequently, these software routines serve as a filters for similar future mischief (see for instance Northcutt, 1999). Although this time tested approach is the backbone of current computer security systems, its primary shortcoming is that such filters can only be written and implemented once the exploit has occurred, and perhaps succeeded. Herein, we introduce the paradigm shift of an adaptive filter, that is self-constructing, autonomously building a model of normal network activity by constantly monitoring bona fide packets and audit logs. Thusly habituated to typical network traffic, this adaptive filter responds to the slightest deviation from network status quo, thereby enabling an intrusion detection system (IDS) that anticipates future attack scenarios as well as potential system faults.
1.0 Introduction - The major advantage of artificial neural networks over the typical heuristic programming paradigm, is that a human developer need not understand the rules underlying a given conceptual space. Rather than require a programmer to think of all possible "if-then-else" processes that embody the problem, an artificial neural network is effectively exposed to many raw data patterns or scenarios within the domain of interest. During this training process, the network absorbs all of the underling heuristics concealed within these patterns. Close scrutiny of this rule absorption process reveals that the individual processing units, or neurons of the neural network, grow 'logic circuits' among themselves so as to automatically capture the implicit algorithms involved. Needless to say, this is an invaluable modeling technique, especially when the process we intend to model is highly complex or resistant to timely human analysis.
Even though the packet stream on a modest local area network (LAN) may appear bewildering to a casual human observer, there are many functional constraints buried within the torrent of bytes. For one, very distinct temporal relationships are implicit within the parade of time stamps presented, reflecting a mixture of high-speed machine activity and slower, more tentative human-originated events. Distinct correlations are present between source and target IP addresses, indicative of the statistical frequency with which these machines typically communicate. Furthermore, hex-based packet payloads do not appear in infinite variety, but fall within the mold of just a few basic types. In short, these and many other complex and highly non-linear functional relationships develop between the various attributes of the packets, that in turn may be captured within the spontaneously growing connection weights of a training artificial neural network.
Pioneering efforts have already been made in exercising the clear advantage of neural networks (ANN) in building intrusion detection filters (Cannady, 1998). The general approach has been that of training ANNs upon historical packet capture databases to distinguish 'good' and 'bad' traffic by activating one of two corresponding output units, or flipping the state of a single output node. During the course of this off-line training, the network develops an internal logic so as to generalize whether a given packet or audit log record is suspect. Provided we are confident in having collected a balanced set of sample data (i.e., equal numbers of benign and malign events), we consider this approach sound. However, rarely do we attain such a balanced database in which the gamut of all exploitative scenarios is spanned. The fact is that we always have abundant examples of benign network activity on hand. Such data may be collected en masse simply by running packet capture programs for long time periods. On the other hand, we typically have only a limited sampling of potentially pathological events. Thus we see the emergence of a significant problem: Hackers are perpetually inventing new and previously unanticipated techniques to compromise information infrastructures. Therefore, we can never attain what would generally be acknowledged as a statistically balanced set of exemplars to train these so-called hetero-associative nets. In the following sections we show how this inherent sampling problem is solved through the use of what are called auto-associative networks.
2.0 Enabling Technology #1, Auto-associative Group Membership Filters
Although there is significant appeal in applying artificial neural networks (ANN) to IDS applications, the simplistic approach of training an ANN to map from some network traffic pattern to a "yes-no" decision regarding its acceptability has some obvious statistical sampling problems. However, a paradigm shift in ANN-based intrusion detection is realized when we abandon the idea of collecting both benign and malign traffic patterns, instead amassing plentiful examplars of normal network activity. In this way we may rapidly form a model of acceptable network traffic that absorbs the implicit functional constraints needed to pronounce such traffic "good."
If an ANN consisting of three or more layers is trained to reproduce its input pattern at its output layer, the internal logic that develops within this network is far from simple. The output patterns of this auto-associative multilayer perceptron (MLP) form not from a straightforward duplication or 'fan-out' of input states, but from a complex encryption taking place within the hidden layer(s), with subsequent decryption occurring at the net's outputs. Once trained, careful dissection and analysis of this auto-associative network shows that the inputs are reconstructed at the net's outputs on the basis of many functional constraint relationships that are automatically absorbed within the net through cumulative exposure to training patterns.
The implicit constraint relations now contained within the auto-associative network are of immense practical value when considering whether input patterns, perhaps never before seen by the net, belong to the group of interrelated patterns previously shown to the net in training. In general, if an input pattern P, consisting of a series of vectorial components or micro-features, is applied to the inputs of this net, then the pattern is disassembled within the preliminary weight layer(s) and then reconstructed via the absorbed functional constraints at the output layer. To achieve an accurate reconstruction of the input pattern, two conditions must be met: (1) frequently encountered input features common to the group of training patterns, must be sensed within the net's intermediate layer(s), where feature detection capacity spontaneously develops during training, and (2) such sensed entities must obey some previously encountered interrelationship that has been cumulatively learned by the net and incorporated within its final weight layer(s). A moments reflection should convince the reader that these are the underlying processes within human cognition that allow us to classify a thing or event as belonging to some previously recognized genre. Subconsciously or not, we decide whether an entity possesses certain critical features, and then assess how these features are ordered or interact. (i.e., An object is regarded as an automobile if it has certain features that include an engine, tires, steering wheel, etc. and all of these components are combined in some customary geometry and topology.)
Thus, if the pattern applied to an auto-associative network is accurately reconstructed through the recognition of critical features and their relationships to one another, then the Euclidean distance between input and output patterns, | P - P' | = δ, should approach zero, effectively signifying group membership (see Figure 1). If d assumes larger values, then the network has detected one or more feature or functional anomalies in the input pattern that disqualify it as a member of the group of patterns previously shown to the net. Here, just as in human cognition, some implicit or explicit threshold delta is set to distinguish members from non-members. Put in other words, the group membership network has absorbed the "zen" of the group of patterns it has been exposed to in training and can rapidly discern other potential member patterns through their intact feed forward passage through the auto-associative net.
This unprecedented use of an auto-associative network is one of the primary arts taught by US Patent 5,852,816 (and its foreign filings), thus enabling a very powerful means of building fault detection systems without the need for explicit heuristic knowledge about the system being monitored. Needless to say, this development has significant repercussions to network security. We note however that IDS neural networks are typically trained off-line, typically only after a number of human judgments have been made and committed to concerning the nature of the training and neural architecture. To make such fault-detecting ANNs totally autonomous and capable of nearly real-time intrusion detection, we introduce a second enabling technology, the Self-Training Artificial Neural Network Object or "STANNO."
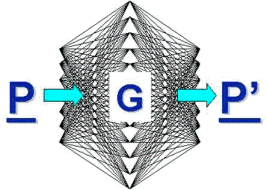
Figure 1. An Auto-Associative Network Used As a Group Membership Filter. If such a network is trained upon numerous patterns representing a group, G, of interrelated things (i.e., benign network packets), then the passage of any pattern through the net, representative of that group of exemplars, regenerates itself at the network's outputs (i.e., | P - P' | >> 0). If on the other hand, a non-representative pattern is propagated through the net, a significantly different output pattern is generated (| P - P' | >> 0). ( U.S. Patent 5,852,816)
3.0 Enabling Technology #2, The Self-Training Artificial Neural Network Object (STANNO)
Probably the most succinct definition of the Self-Training Artificial Neural Network Object (Thaler, 1996, 1998a,b) is that of two neural networks, one of which is training the other. Rather than utilize a traditional sequential training algorithm, such as back-propagation (Rumelhart, 1986), the parallel distributed algorithm, or ANN, responsible for training its mate, learns how to adjust the weights and biases of an untrained net until an accurate model fit is achieved. Furthermore, both networks of the STANNO may be topologically folded into one another, to create one seamless network that trains simply by the introduction of training patterns. Typically implemented in C++ and Java, these STANNOs train at extraordinary speed on ordinary desktop PCs, allowing the rapid training of complex neural network models incorporating, if need be, millions of individual processing units. Implementing such self-training networks as object-oriented programming (OOP) class templates, the number of such objects instantiated on a given machine or local area network (LAN), is limited only by the available CPU and RAM. Each of these STANNOs may train totally independently of operator assistance in an unsupervised mode, or be readily isolated from the other STANNOs and then trained by a human mentor via supervised learning.
If a STANNO is made auto-associative and shown interrelated patterns, then it becomes an autonomously training group membership filter that in very short order learns to identify related patterns within continuous data streams. It trains in unsupervised mode, since no human operator is telling it what its outputs should be. It is simply learning to reproduce whatever input patterns are applied to it. If need be, we may create multiple instances of the STANNO class on the same machine (Figure 2), with each of the created objects pointed toward a different group of data features that we need to simultaneously monitor for conformity. In effect, this swarm of STANNOs is taking multiple perspectives on data streams to alert users to any arising anomalies.
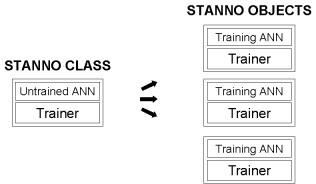
Figure 2. In contrast to conventional neural networks, the STANNO is integrated with its own highly compact training algorithm. As a result, an instance of the original STANNO class may continue to train indefinitely, as additional patterns are shown to it. Multiple STANNO instances may take independent perspectives on arriving data streams.
4.0 The LITMUS Intrusion Detection System
Both the auto-associative group membership scheme, and the Self-Training Artificial Neural Networks (STANNOs) may be combined into a very robust, sensitive, and fully automated intrusion detection system called LITMUS (Live Intrusion Tracking via Multiple Unsupervised STANNOs). In the near term, LITMUS is meant as a complementary technique to conventional signature-based intrusion detection systems. We note however, that given a large sampling of known attack signatures, STANNO-based group membership filters may train upon these patterns, and inevitably replace all forms of heuristically-based attack recognition systems. The major advantage of such a paradigm shift would be the probabilistic identification of attacks rather than the typical "black and white" classification. Therefore, a particular group of packets may for instance correlate to within 90% of known "syn-flood" attacks, perhaps alerting an analyst to a new genre of network abuse that is derived from the classic denial of service scenario.
Figure 3 illustrates a single instantiation of a Windows-based LITMUS program, implemented in Java, that has been 'pointed' toward a target file that is serving as a buffer for LAN packets and being rapidly refreshed by the packet capture program, WINDUMP. The TRAIN button initiates STANNO training, allowing the creation of a neural network model of network traffic in just a few minutes. Note that at this stage, packets no longer appear in the typical chronological order of timestamps, but rather in an ordered list that ranks each pattern in terms of its intrinsic novelty, as measured by the group membership metric, d. Therefore, reading from top to bottom, we observe the progression from the most 'bizarre' packets (at the top) to the most 'mundane' (at the bottom). Furthermore, families of similar packets have automatically 'clumped' together providing a very high-dimensional sort (i.e., 200 dimensional in this case) into similar packet classes. This dynamic process of autonomous classification is viewed within the application's interface, as the underlying STANNO continuously trains.
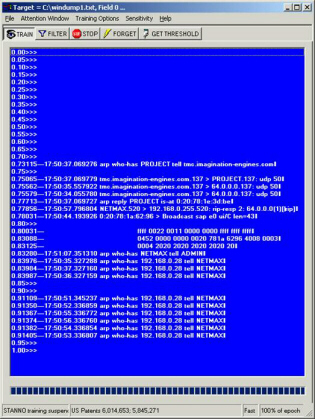
Figure 3. The LITMUS application autonomously classifies network packets in nearly real time, into similar families, while building a model of normal network traffic. In this display, the most recently captured packets from the IEI local area network are displayed in descending order of their novelty. Therefore, the most anomalous packets bubble to the top of the LITMUS display area. (Note that the vertical scale to left represents the quantity (1 - d)
Over a matter of just a few seconds, similar packets gravitate toward one another within the display. (It is to be noted that the proprietary STANNO classification scheme is at least 10 times faster than traditional self-organizing map schemes, which are not in the least autonomous processes)
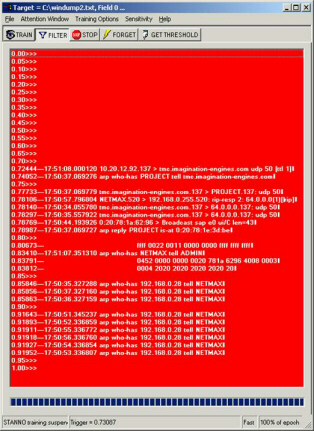
Figure 4. Having set a trigger threshold at the packet second from the top, introduction to the LAN of a known malicious UDP packet (top) triggers the application's alarm and turns the display background a bright red. Note that this UDP packet has bubbled to the top of this recent capture.
Once the STANNO has trained itself for a short time, the operator may make a value judgment as to where the demarcation between normal and abnormal traffic lies, within the vertical scale presented in the display. The operator may elect to name the highest outlier (i.e., the topmost packet) as the dividing line between routine and pathological network activity. Procedurally, this task is accomplished simply by left mouse-clicking on the uppermost packet, so as to create an automatic trigger point. Having set this threshold, we illustrate in Figure 4 what happens when an exploitative packet now enters the mix. In this illustrative experiment, we have artificially inserted a known malicious packet into the LAN (from the "Capture the Flag" archives of DEF CON 2000, http://www.defcon.org/). The suspect packet automatically floats to the top of the latest group of packets, above the preset threshold, thus tripping the application's alarm system. The background changes litmus paper style from a blue to red coloration. Note that we have found that this is a very ergonomic design, since a network analyst may judge the health of their computer network, from across a room, by the color of the LITMUS display. The return to network normalcy is accompanied by the continuous transition of the display area's background color from red, to purple, and finally back to blue.
In our beta version of LITMUS, the user interface contains a toolbar and a series of buttons that control the various STANNO functions (Figure 4). As previously mentioned, the TRAIN button sets the underlying STANNO to its training mode, wherein packet patterns are automatically parsed and converted to a binary ASCII representation. For each ASCII input wave through the STANNO, a corrective wave counter-propagates, iteratively modifying connection weights until a model fit to network activity is achieved. In contrast to the TRAIN mode, the function of the FILTER button is to enable forward propagation of packets through the STANNO, without any further weight updates. Since no training is involved in the FILTER mode, the STANNO may more quickly respond to the typically high rate of packet turnover within computer networks. The STOP button halts the STANNO, either in its TRAINING or FILTERING mode.
Within the application's main menu, we see the FILE Option, by which we may specify the text file that serves as the STANNO training target (i.e., the buffer file between the packet capture program and the Java application). Because of the program's flexible design, the STANNO may likewise be pointed toward system logs in order to perform similar anomaly detection and autonomous classification functions, either in real time, or within retrospective analyses. The ATTENTION WINDOW menu allows the operator to move the STANNO's focus from one field of the packet stream to another. It is through this feature that the user may select perspectives on time-stamps, source IPs, destination IPs, etc.
Under the TRAINING OPTIONS menu, we may vary the number of computational neurons incorporated within the STANNO's hidden layer. The faster training modes incorporating 50 computational neurons are intended largely for demonstration purposes, while the slowest setting is reserved for the actual operation of the system within normal function, wherein typically hundreds of hidden layer units are recruited.
Finally, the SENSITIVITY menu allows the user to manually adjust the sharpness of the LITMUS color transition from blue (normalcy) to red (pathology). The high sensitivity setting enables a rapid color transition.
In an effort to optimize LITMUS performance, we have recently developed a newer C++ based STANNO that can train on as many as a thousand 300 character packets per second, on a 1 GHz, Pentium 4 processor. The application itself occupies a very small footprint in memory of only 300 KB.
To profit most from the LITMUS IDS system on an actual LAN, one would create several instances of the LITMUS application, each looking at different perspectives of the arriving packet stream, as a packet capture program (i.e., TCPDUMP or WINDUMP) transfers packets to a buffering text file. The Java routines asynchronously access this text file, enabling each to simultaneously train on different aspects of the same packet stream.
In Figure 5, we see three separate instances of the Java-based STANNO training on and forming models of timestamps, source IPs and target IPs, respectively (note that any packet fields may be examined). The analyst may independently set alarm trigger thresholds within each of these instances of LITMUS.

Figure 5. Three Separate LITMUS Instances Running Simultaneously. Many instances of LITMUS may be simultaneously run on the same host machine, each taking on various perspectives to the packet stream. Here, the leftmost instance is forming a model of network timestamps, the middle, source IPs, and the rightmost, destination IPs. Note that in this particular mode, LITMUS is evaluating the group membership of groups of packet attributes. Therefore, on the left, the sequence of time stamps floats as a group, up or down, depending on the novelty of that time sequence.
STANNO IDS filters are flexible enough to allow autonomous classification of most text files. Including typical audit log files. Therefore, simply pointing the STANNO filter toward the audit log of interest, will automatically rank entries in terms of their novelty, with the most suspicious activity again floating to the top of the display. Furthermore, since all records have been autonomously sorted into similar families, we may readily identify other such traffic, potentially related to any record indicating a pathology.
n Figure 6, for instance, LITMUS reveals the Nimda worm attempting to gain access to root.exe on a Microsoft IIS server. Note how this audit record has automatically bubbled to the top of the display area. The time to isolate this pathology was approximately 10 seconds from its logging, via IIS, on a 1 GHz, Pentium 4 processor. This application isolated these suspicious events from 50,000 other audit log records.
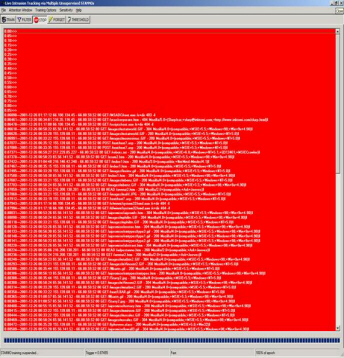
Figure 6. In nearly real time, LITMUS identifies the appearance of the Nimda worm on an IIS server as it attempts to gain root access. Note that this application has been given no explicit information about the Nimda exploit. These novel events that include rare spidering records, have bubbled to the top of 50,000 audit log records for the IEI web site, from 12/26/01 . Other records shown represent less frequently accessed web pages and resources.
5.0 Summary
In the preceding sections we have introduced a major paradigm shift in network intrusion detection, capitalizing greatly upon the well-known ability of ANNs to serve as self-organizing, constraint satisfaction devices. Complementing this ability and enabling very adept IDS systems, is the advent of two new neural network technologies, (1) the auto-associative group membership filter, and (2) the Self-Training Artificial Neural Network Object (STANNO). When all of these capabilities are combined into a single application, we are able to identify not only established attack signatures, but also anticipate newly devised attack strategies.
In short, LITMUS allows network analysts to view LAN traffic from a totally new perspective. Rather than witness computer network activity on a chronological basis, events are nearly instantaneously ordered from the mundane to the exotic. Where exactly to draw the line between routine and anomalous is entirely at the analyst's discretion.
6.0 References
Thaler, S. L. (1996). Self-Training Neural Nets, PC AI, Nov/Dec, '96, 32-34.
Rumelhart, D. E. (1986). Parallel Distributed Processing: Explorations in the Microstructure of Cognition, Volume 1: Foundations, MIT Press, Cambridge, MA., 318-362.
Thaler, S. L. (1998a) Non-Algorithmically implemented artificial neural networks and components thereof US05814152 09/29/1998.
Thaler, S. L. (1998b). Neural network based database scanning system US05845271 12/01/1998.
Cannady, J. (1998). Artificial Neural Networks for Misuse Detection, School of Computer Information Sciences, Nova Southeastern University, Fort Lauderdale, FL 33314.
Northcutt, S. (1999). Network Intrusion Detection: An Analyst's Handbook, New Riders Publishing, Indianapolis, Indiana.
7.0 Acknowledgements
I would like to thank Mr. Rusty Miller , Director, Advanced Technology, Critical Infrastructure Protection Group, Veridian Information Solutions, for his useful inputs to this paper.
