Self-Training Artificial Neural Network Object (STANNOs)
 Summary - Be careful when AI practitioners state that artificial neural networks (ANN) are self learning! What they really mean to say is that a script (i.e., a training algorithm) is governing the development of connections between neurons so that the net as a whole can absorb knowledge. So, the network can certainly become wiser, but it isn't in any way mentoring itself. Instead, it is being trained by an external computer algorithm.
Summary - Be careful when AI practitioners state that artificial neural networks (ANN) are self learning! What they really mean to say is that a script (i.e., a training algorithm) is governing the development of connections between neurons so that the net as a whole can absorb knowledge. So, the network can certainly become wiser, but it isn't in any way mentoring itself. Instead, it is being trained by an external computer algorithm.
In 1996, with the assistance of a Creativity Machine, our founder discovered how to build a new kind of ANN that learned without recourse to such a script. In effect, it was an artificial neural network (neurons, and connections, sans the traditional training algorithm) that could spontaneously absorb knowledge. ...Oh, and by the way, it was orders of magnitude faster and more efficient than any other neural network learning scheme, enabling ANNs having billions of connection to train on mere Pentium-based PCs. Furthermore, collections of such "Self-Training Artificial Neural Network Objects", or STANNOs, could connect themselves into compound neural networks, what we call SuperNets. In effect, brains could now self-assemble themselves in silicon!
Details - When a machine learning expert talks about training a net, what he or she means is that a very cleverly contrived computer algorithm is being used to adjust the signs and magnitudes of the connection weights therein, allowing it to accurately absorb memories and complex relationships inherent within its training patterns. Typically, these training algorithms are readable by a neural network savvy computer programmer. Note that once the trained neural network is detached from this training algorithm, the network can no longer be trained, and hence cannot adapt to new data within its environment.
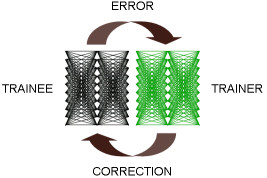
IEI neural networks break this paradigm completely in that no human-invented mathematics are involved. We simply combine an untrained neural network (i.e., a trainee) with a network that has learned by example how to train another net (i.e., a trainer). Furthermore, we interlace trainer and trainee networks together so as to create a monolithic neural network that automatically learns when introduced to data. We may build class templates (i.e., cookie-cutters for more of these self-learning nets) through which we may instantiate hundreds or thousands of these so-called "Self-Training Neural Network Objects" or STANNOs on common PCs. Working as a cooperative swarm, these STANNOs may collectively exhaust all potential discoveries concealed within vast databases. If, instead of using pre-trained neural networks in the Creativity Machine, we use STANNO modules, we produce a generative neural architecture that can learn from its own successes and failures.
More recent advances in this technology allows episodic learning to take place within these multilayered neural nets. Said simply, STANNOs may be offered just one exposure to a training exemplar, and it is permanently absorbed, either as a memory or a relationship, in spite of subsequent exposure to other training patterns. This capability allows Creativity Machines to learn from their successes and failures without having to maintain a database of past training exemplars.
STANNOs may also connect themselves into impressively large, compound neural networks. Rather than think of the fundamental processing units as neurons, the building blocks of these immense neural structures are actually smaller neural networks. If each of these sub-networks can, for example, model the behavior of some hardware component (i.e., electrical devices such as transistors, capacitors, resistors, etc.) that may then spontaneously connect themselves into functioning, virtual systems (i.e., a transistor radio or digital computer) showing us the required topology between components to attain the desired function (Thaler, 1998). Further, if each sub network represents some fundamental analogy base, these neural modules may now spontaneously connect themselves into human-interpretable theories.
In effect, STANNOs may effectively dock and interconnect with one another so as to form brain-like structures, wherein we observe the loose division of labor among component networks, as in the human brain. In this way, we allow large collections of STANNOs to 'grow' complex brain pathways for use in our advanced machine vision projects and robotic control systems. Rather than being simple neural cascades composed of interwoven neural network modules that are pre-trained and static, these SuperNets, as they are called, are composed of individual neural network modules that are training in situ, in real time.
STANNOs also form the basis of our highly advanced and flexible neural network trainer called PatternMasterTM, allowing users to produce trained neural network models at unprecedented speeds. Because of their extraordinary efficiency, they can handle immense problems even on desktop PCs, easily dealing with genomics-sized mapping millions of inputs to millions of outputs. Furthermore, using STANNOs, the neural network model can be interrogated even as it trains!
